广州班车系统指南:班车线路规划与数据驱动管理升级-飞马舒行
2026-05-26
广州班车系统的选择,难的并不是买一套系统,而是买完之后发现用不起来。2025年广州一家制造型企业花了三十多万上了一套班车管理平台,上线三个月,司机还是习惯用微信群接人,行政还是靠Excel表格排班。系统成了摆设,钱打了水漂,本该降本增效的工具变成了给服务商福利。这也不是个例,很多广州企业在班车系统平台选择时,往往只看功能清单够不够长,却忽略了一些实实在在的基础功能点,如班车线路规划能力、班车数据闭环和本地部署落地经验这些真正能决定能不能用起来的东西却没有得到实际性的关注。
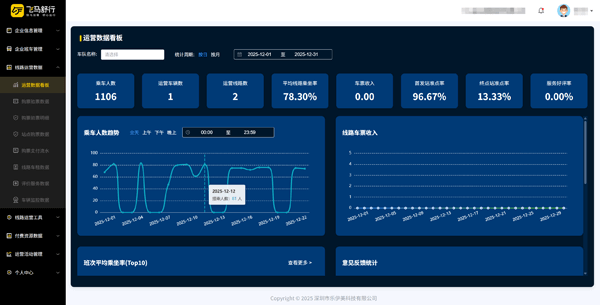
广州班车系统的选择应该从广州企业通勤的实际痛点出发,讲清楚线路规划算法怎么选、数据驱动管理怎么做,以及企业最容易踩的坑点。广州企业为什么需要班车系统?先说一个真实场景。
广州开发区一家电子信息企业,员工分布在黄埔、天河、番禺三个区。每天早上,8辆大巴从三个方向出发,但线路是行政小王去年凭导航工具画的。员工不停地抱怨:绕路太远了,我坐班车比坐地铁还慢;企业财务那边也头疼,每个月班车费用对账,司机报一个数、行政记一个数、财务算一个数,三个数永远对不上。这也不是这家企业独有的问题,广州大量企业都这样:车在跑,数据在飘,管理在猜。
广州黄埔-番禺跨区通勤管理难

广州的城市格局决定了跨区通勤是刚需。黄埔到番禺、黄埔到南沙,这些跨区路线单程动辄四五十公里,途经的拥堵节点多——黄埔大桥早晚高峰常常堵成停车场,科韵路、华南快速也不是省油的灯。
跨区通勤意味着线路长、站点多、变量大。一个站点时间拖5分钟,整条线路就可能延误20分钟。靠人工排班,很难把这些变量都算进去。而如果员工等不到车,或者上车后发现绕了远路,体验直接拉垮。地铁2号线南延段开通后稍有缓解,但对于远离地铁站点的工业园区来说,企业班车依然是不可替代的通勤方案。
广州科学城片区线路规划复杂
科学城片区的线路规划是另一个典型难题。科学城部分园区长期没有地铁覆盖,公交线路也少,园区企业招工难、员工出行难的问题一度非常突出。虽然后来增加了交通便民线,但企业班车的需求依然旺盛,公交无法做到门到门,也做不到按企业需求定制时刻表。
更棘手的是,科学城企业员工居住地高度分散。有人住在增城,有人住在白云,还有人住在番禺万博。如果一条线路要同时覆盖多个方向,不靠算法辅助,纯靠行政拍脑袋,班车线路必然越绕越远,上座率越来越低。
传统班车管理方式数据缺失
传统班车管理的经典画面是这样的:行政建个微信群,每天在群里通知:明天3号线司机老张请假,换成李师傅;月底问司机这个月跑了多少趟,司机翻翻本子报个数;财务拿着一堆纸质单据逐笔对账。
这种班车模式下,班车运行的数据是残缺的。谁今天坐了车、哪条线空座率高、哪个站点等候时间长——全凭感觉,全靠估算。没有准确数据,优化就无从谈起。更别说当企业规模扩大、线路从3条变成10条的时候,人盯人式的管理根本撑不住。
广州班车系统选型,到底看什么?
搞清楚为什么需要之后,关键问题来了:广州班车系统选型,到底看什么?
市面上班车管理软件不少,功能列表都写得天花乱坠。但如果你仔细对比,会发现真正拉开差距的往往不是功能数量,而是几个核心能力的深度和精细化。下面从几个方面说说选型该盯住什么。
班车线路规划和通勤班车排班调度能力,这是班车系统最核心的差异化能力,没有之一。
传统班车线路规划靠什么?靠行政画地图、司机凭经验、员工提意见。这种方式在小规模(2-3条线路)时还能凑合,一旦线路多了、员工分布散了,就显得力不从心了。将近七成五的企业班车线路存在迂回、空驶率高的问题,根源就在班车线路的规划方式上。
AI线路规划算法的思路完全不同。它把员工住址、上班时间、路况数据、车辆载客量等参数全部输入模型,通过遗传算法或蚁群算法求解最优路线。实际效果?据飞马舒行服务广州企业的数据显示,AI线路规划可降低空驶率20%以上,部分线路优化效果更明显。
但这里有个关键点:算法也不是万能的,得看它能不能适配广州的路况特点。广州的单行道、限行区域、城中村窄路,都是算法建模时必须考虑的约束条件。选型时一定要问清楚:算法是否支持自定义路网约束?有没有广州实际线路的优化案例?
班车排班调度方面,广州企业的需求比想象中复杂。早班、晚班、周末加班车、临时加车,不同场景对应不同的排班逻辑。一套好的班车系统,至少要支持多时段排班,同一车辆在不同时段跑不同线路、灵活加车减车、跨线路调度、节假日特殊排班这些能力。如果班车系统只能做简单的一条线一辆车式的排班,面对复杂的实际需求就会捉襟见肘。在做班车系统服务商的选择时,你想想拿企业最复杂的一周排班需求做测试,看系统能不能撑住。
验票核销和数据报表,验票方式看起来是小事,但它直接影响两个东西:乘车体验和数据准确度。
目前主流的班车验票方式有三种:
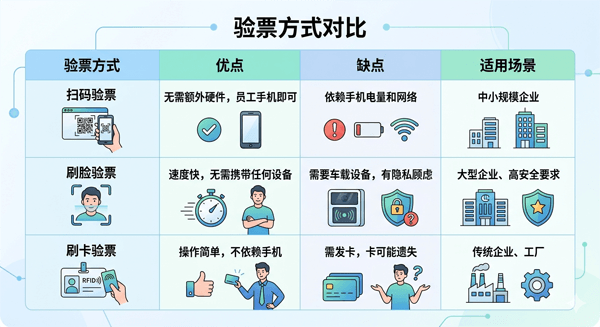
飞马舒行的班车系统同时支持这三种方式,企业可以根据实际情况灵活选择。关键是,无论哪种方式,验票数据必须实时上传到管理后台,否则数据驱动管理就是空谈。
班车验票数据沉淀进来了,就得看报表。很多企业在选型时容易忽视报表的完整性。有些班车系统只管运营——车辆在哪、谁坐了车、线路怎么走。但运营数据如果和财务数据是割裂的,意味着你每个月还得手动做一轮对账。运营+财务一体化报表,才是数据驱动管理的基础。具体来说,一套完整的报表体系至少包含运营报表(每条线路的乘车人次、空座率、准点率、延误原因)、财务报表(每月/每季度费用明细、单车成本、人均通勤成本)、趋势报表(同比环比变化,辅助判断是否需要增减线路)和异常报表(自动识别空座率突增、费用异常波动等情况)。
快速部署能力和广州落地经验
在选择时大家容易忽略一个问题:这套系统从签约到真正跑起来,要多久?
有些系统架构复杂、定制化程度高,实施周期动辄3-6个月。但对于广州企业来说,通勤问题等不了半年。员工每天都在坐车,每天都在抱怨,行政每天都在被催。7天能上线的系统,和半年才能上线的系统,对企业来说完全是两种选择。
飞马舒行的班车管理系统之所以能做到7天上线,核心原因是产品化程度高——企业端、员工端、司机端、车队端四端开箱即用,标准功能不需要二次开发,只需要配置企业自己的线路和人员信息。当然,如果有个性化需求,定制化周期会相应延长,但班车基础功能的上线速度是选择系统时必须考量的硬指标。
广州班车系统选型常见误区
最后说说广州企业选型时最容易踩的几个坑。功能越多越好?未必
这是最常见的选型陷阱。有些厂商在演示时恨不得把所有功能都展示一遍,看起来非常强大。但回到你的实际场景:你需要同时支持5种验票方式吗?你需要对接8个第三方系统吗?功能越多,系统越复杂,学习成本越高,落地难度越大。
选型时应该反过来想:你最核心的3个需求是什么?把这3个需求做到极致的系统,比什么功能都有但都半吊子的系统靠谱。
忽视部署周期和实施难度
前面已经讲过部署速度的重要性,这里再强调一点:实施难度不仅影响上线时间,更影响使用率。
一套系统如果操作复杂、界面难用、员工端体验差,上线了也没人愿意用。司机觉得麻烦就不用,员工觉得扫码不如直接上车就不用,行政觉得还不如Excel方便就不用,系统变成了纸面系统。选型时,一定要让实际使用者(行政、司机、员工代表)参与试用,而不是只让IT部门或采购部门看演示。
只看产品不看服务
班车系统不是买完就完事的。线路需要持续优化,排班需要动态调整,系统需要迭代升级。如果服务商的售后响应慢、本地没有服务团队、遇到问题只能远程排查,你的系统迟早会变成僵尸系统。特别是广州这种路况复杂、企业需求多样的城市,有没有本地的实施和运维团队,直接决定了系统能不能长期用下去。
广州班车系统选型,说到底是在选三样东西:能真正落地的线路规划能力、能跑通决策闭环的数据驱动体系、能在广州帮你扛事的服务团队。如果你正在做广州班车系统选型,建议先从这几个问题出发:你的线路规划需求有多复杂?系统的AI算法能不能适配广州的路况特点?你需要的数据闭环是什么样的?运营和财务数据能不能一体化呈现?这套系统多久能上线?服务商在广州有没有成功案例?想清楚这些问题,选型就不容易跑偏。